Autonomous Intelligent Machines and Systems: Active Embodied Intelligence
Autonomous Intelligent Machines and Systems: Active Embodied Intelligence

Introduction
Embodied intelligence requires a rich perception of the physical world. For robots to robustly interact and collaborate in the real world, they need to be re-designed to overcome their current limitations in sensing capabilities. At present, robots are too specialized, uncooperative, and unsafe to be effective at scale. We need a new generation of robots that can understand their environment with unprecedented acuity. Below, we’ll cover six critical aspects of robotic intelligence: Sensing, Acting, Interpreting, Navigating, Coordinating, and Collaborating. Advancements in these key areas will help lay the foundation for advanced robotics. [1]
Sensing
Embodied AI requires advanced sensing and perception technologies to decode the physical world, which is currently lacking in robotics. One significant gap is reliable force feedback, or “touch sensing.” Interesting areas in this vertical include soft robotics and mechanical intelligence — tactile experiences are crucial for manipulation tasks, as well as robot-robot and robot-human interactions. It is important to have a scalable plan for tactile perception. Software, hardware, and mechanics need to converge to enable robots to engage in tactile-aware physical interaction. [2]
The integration of soft sensing remains an ongoing challenge. Currently, soft robotic arms with infinite degrees of freedom are being developed to execute dexterous tasks in busy and cluttered environments. Stimuli must be both produced and perceived within a robotic structure to support closed-loop control and spatial awareness. [3]
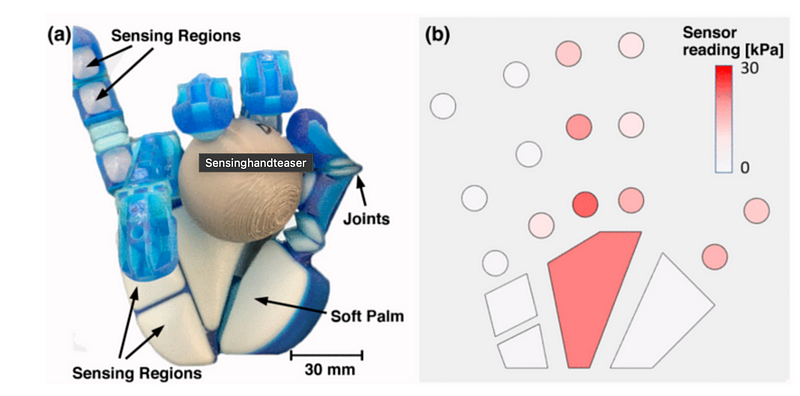
The integration of distributed sensing in soft robotics is currently inadequate. Humans rely on distributed tactile sensing in their hands for the dexterous manipulation of delicate objects. In recent years, soft robotic hands that are adaptable and safe have received increased attention. Building such a robotic arm is highly complex — see the example below.
Visual data acquisition is a relatively simpler problem compared to collecting tactile data. Tactile data collection is not trivial; it is time-consuming and sensor-specific. Consequently, deploying machine learning algorithms on tactile data becomes challenging, particularly in robotics applications where low error rates are crucial.
One way to address this issue is by creating synthetic tactile datasets or collections of synthetic tactile sensor responses using generative models, specifically for use in downstream robotics applications. For example, the approach described in the “Touching a NeRF” paper by Zhong and colleagues [5] involves taking RGB-D images — images that include both color and depth information — as inputs and generating corresponding “tactile images.” This is one method to attempt to create realistic tactile data.
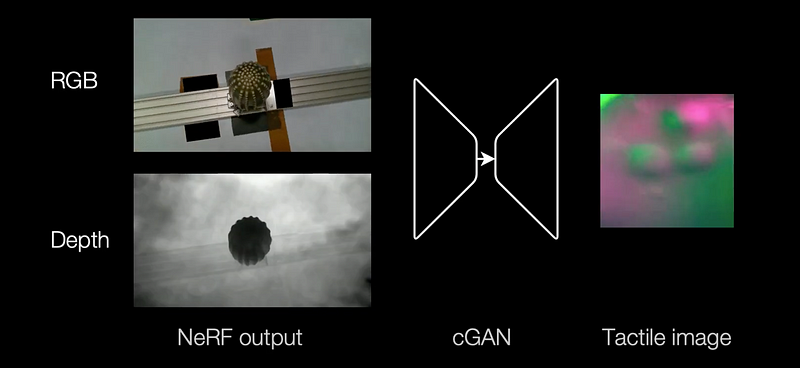

Note: NeRF stands for Neural Radiance Fields, a technique used for synthesizing highly realistic 3D scenes from 2D images. It leverages deep learning to model a continuous 3D scene as a neural network that can generate novel views of the scene.
Note: A cGAN, or Conditional Generative Adversarial Network, is a variant of the traditional Generative Adversarial Network (GAN) that allows for the conditional generation of data.
Interpreting
Currently, the biggest hurdle for robots in easily interpreting their environments is the lack of available labeled training data. Object detection in vision and 3D are well-established fields and are commonly leveraged to build robots; however, this approach does not work effectively at wide scales. We need new methods that reduce the required supervisory input to zero and allow robots to learn unsupervised at scale and across multiple domains — not just in vision and 3D, but perhaps in tactile sensing as well.
We need a way to develop robust robot metacognition — the awareness and understanding of its own processes — enabling a robot’s ability to monitor, control, and plan activities, i.e., enabling robots to think about thinking. Robots need to be able to decide how to allocate processing resources and adjust their approaches to problem-solving and learning on the fly.
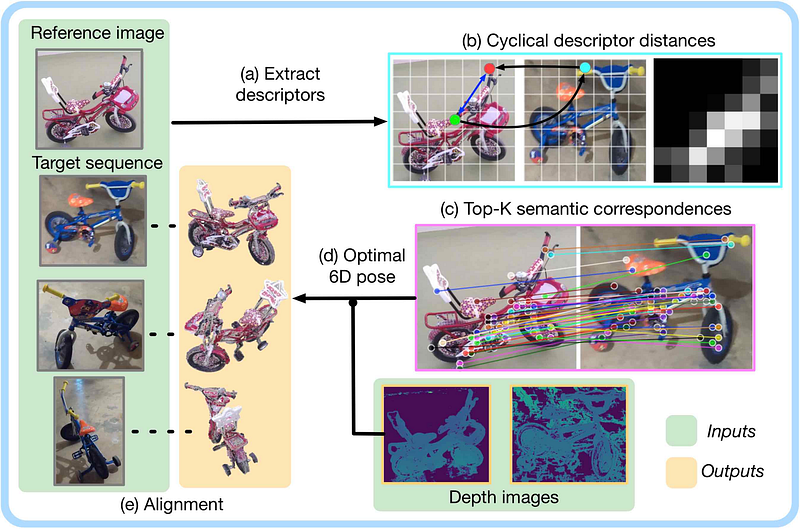
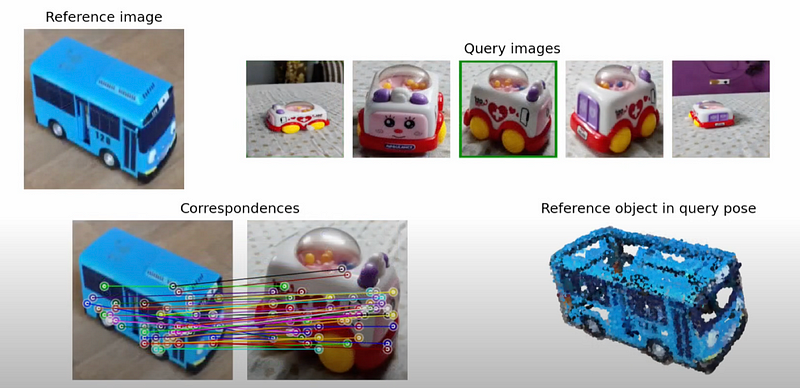
An example of an approach that is strategically closer to this goal is object pose estimation without the need for pose-labeled datasets, using a self-supervised vision transformer to solve the pose estimation problem — see below [4].
Acting
In the wild, robots will need to be able to use and re-use various skills, including those learned previously, as well as new ones acquired on the fly. Advancements in deep learning are bringing about systems that learn end-to-end and develop reactive control policies directly based on sensor data. However, the current issue is that these systems require infeasible amounts of labeled data to become agile enough to be usable. Robots need to learn new skills using cross-modal demonstrations and train within an established and curated world model. Versatile goal conditioning using probabilistic algorithms will make acquired skills reusable through active learning.
For example, quadruped robots are maturing rapidly and can now traverse a variety of unstructured terrains. However, one thing they still cannot do is vary their gait on the fly; their gaits are selected from a range of styles before setting the robot in motion. (Gait here refers to the pattern or sequence of movements the robot’s four legs follow when it walks, runs, or performs other motions; different gaits, like walking, trotting, or galloping, involve different timing and coordination of the legs.)
Below is an example of a project aiming to change this — the project focuses on learning a latent space and capturing the key stance phases of a particular gait via a generative model trained on a single trot style. (Here, a latent space refers to a lower-dimensional representation of data that captures the underlying structure or features in a way that simplifies analysis or modeling.) Properties of a drive signal map directly to gait parameters such as cadence, footstep height, and stance duration. In effect, the use of a generative model allows for the detection and mitigation of disturbances.
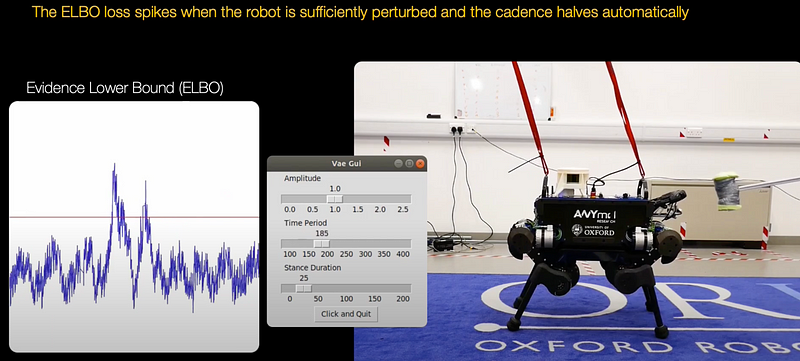
Motion planning framed as optimization in structured latent spaces has recently emerged as competitive with traditional methods in terms of planning success while significantly outperforming them in terms of computational speed. However, the real-world applicability of recent work in this domain remains limited by the need to express obstacle information directly in state-space, involving simple geometric primitives.
The paper below covers an innovate method for robot arm movement / motion planning that improves on traditional approaches by making the process faster and more efficient. Traditionally, robot arm movements involve complex calculations for considering obstacles, which slows everything down as detailed geometric descriptions of the obstacles need to be in place. Why not use machine learning to simplify the process — instead of relying on detailed geometry, why not use a more abstract “learned” understanding of the environment as a structured latent space? Maybe we can integrate effective collision checking into the planning process itself. The paper concludes that it is possible to plan robot movements in new complex environments 10x faster than traditional methods; the robot plans and adjusts its movements in real-time as the environment changes. The team shows that it is possible for a robotic system to be fast enough to enable closed-loop planning in real-world dynamic scenes.

Navigating
Understanding surroundings in terms of location and circumstance is an obvious prerequisite for autonomy. Sensors, processing, cross-modal mapping, and localization can all improve performance in robotics and embodied intelligence. New algorithmic techniques need to be developed for long-term autonomy and robustness. Machine intelligence must be capable across various deployment scenarios — from factory floors to construction sites to homes.
One interesting approach is synthesizing high-quality RGB images and corresponding dense depth maps that are well-aligned with segmentation maps. This method can generate training data for tasks like semantic segmentation and depth completion in autonomous driving contexts.

Note: Semantic segmentation is a computer vision task that involves classifying each pixel in an image into a specific category or class. Unlike object detection, which identifies objects within an image, semantic segmentation labels every pixel according to the object or region it belongs to. For example, in an image of a street scene, semantic segmentation would label each pixel as part of a car, pedestrian, building, road, sky, etc. The goal is to create a detailed understanding of the scene by identifying and categorizing all visual elements at the pixel level.
Note: Depth completion is a computer vision task where sparse depth information — such as data from LiDAR sensors, which only provides depth at certain points — is used to create a dense depth map, filling in the gaps to produce depth information for every pixel in the image. This dense depth map provides a more complete 3D understanding of the scene, which is crucial for tasks like obstacle detection, navigation, and scene reconstruction in robotics and autonomous systems.
Both of these tasks are essential in the context of autonomous driving and robotics, where a precise understanding of the environment is crucial for making safe and effective decisions.
Another interesting approach is the use of highly robust and efficient localization with 3D LiDAR point clouds. The authors below propose a system that models 3D point clouds as fully connected graphs, where each vertex represents a semantically identified object instance and the edges capture the spatial relationships between these objects. This method aims to achieve precise place recognition and 6-Degree-of-Freedom (DoF) pose estimation, making it particularly useful for autonomous vehicles and robotics.
Traditional LiDAR-based localization methods either focus on local geometric details, leading to large data storage requirements, or use global features that might overlook important geometric details. The challenge is to develop a method that is both compact and capable of precise localization and pose estimation.
The authors introduce a method that uses semantic information to create a graph representation of a scene. Each object detected in the 3D LiDAR point cloud is treated as a vertex, with the edges representing the spatial relationships between these objects. This approach combines local geometric information with higher-level semantic understanding, allowing for more accurate and efficient place recognition and pose estimation.
Optimal vertex association across graphs allows for full 6-Degree-of-Freedom (DoF) pose estimation and place recognition by measuring similarity. This representation is highly concise, reducing the size of maps by a factor of 25 compared to the state-of-the-art, requiring only 3 kB to represent a 1.4 MB laser scan.

Coordinating
How can multi-agent systems coordinate to complete tasks more efficiently? These tasks depend on interactions with uncertain, dynamic processes. Uncertainty arises in terms of locations in time and space, as well as continuous new inputs. How can we create large-scale aggregate probabilistic models of coordination between humans and robots, as well as between robots themselves?
One common issue in robot-robot interaction is congestion. For example, in a multi-mobile robot scenario, the robots need to maneuver to avoid each other as they carry out tasks related to logistics, warehouse automation, or other applications for autonomous mobile robots. Congestion can significantly increase the duration of robot navigation actions.
Below is an example of a project where the authors present a multi-robot planning framework that accounts for the effects of congestion on navigation duration. They propose a congestion-aware planning framework that models these effects using probabilistic models to estimate the impact of congestion on the duration of navigation tasks. These estimates are then incorporated into a planning algorithm that generates efficient routes for each robot while considering the potential for congestion.
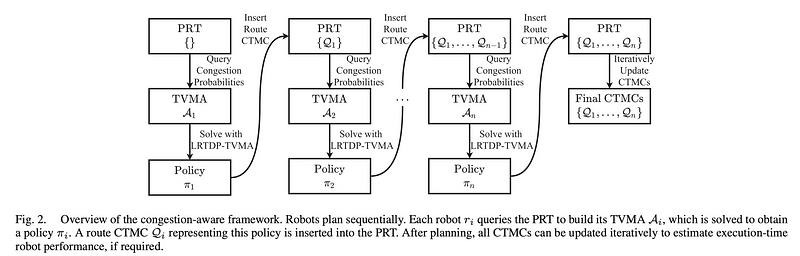
Another interesting coordination solution could be an auction mechanism designed to allocate resources among multiple agents in scenarios where those resources are limited and there is uncertainty about future consumption.
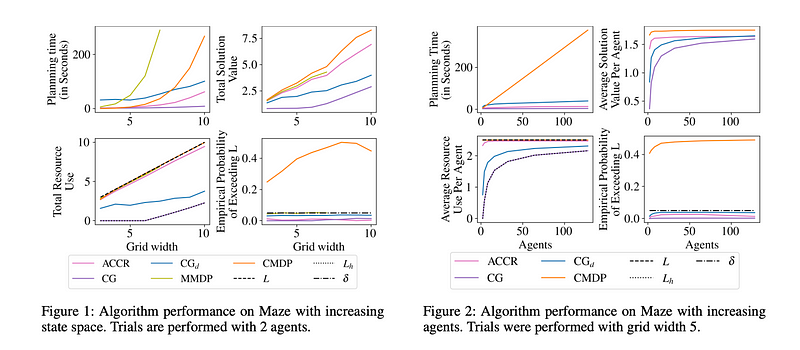
Sharing scarce resources is a key challenge in multi-agent interaction, especially when individual agents are uncertain about their future consumption. The paper below presents a new auction mechanism for preallocating multi-unit resources among agents while limiting the chance of resource violations. By planning for a chance constraint, the authors strike a balance between worst-case and expected-case approaches. Agents can generate bids through multi-objective reasoning, which are then submitted to the auction.
Collaborating
It is important for humans and robots to collaborate safely and effectively in shared spaces. We need to model human-robot interactions in relation to completing joint tasks.
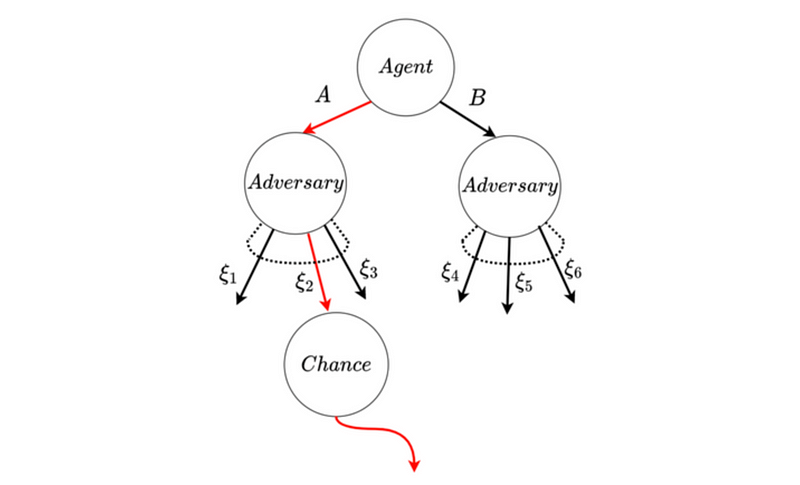
In complex, uncertain environments, ensuring that autonomous systems make decisions that avoid worst-case scenarios is crucial. The paper mentioned below introduces a new approach to reinforcement learning that prioritizes safety by optimizing the conditional value at risk (CVaR) in decision-making processes. The goal is to create a learning algorithm that not only focuses on maximizing expected rewards but is also highly risk-averse. This means that the algorithm accounts for both the uncertainty in the model itself (epistemic uncertainty) and the randomness inherent in the environment (aleatoric uncertainty). By doing so, it aims to develop policies that can avoid bad outcomes even in the most challenging and uncertain conditions.
The authors propose an innovative algorithm that combines Monte Carlo Tree Search (MCTS) with Bayesian optimization to effectively explore and manage these uncertainties. Their approach has been tested in scenarios such as betting games and autonomous car navigation, demonstrating its ability to outperform traditional methods by focusing on risk aversion.
In essence, this research advances the development of more reliable and safer autonomous systems that can operate effectively in real-world environments, where uncertainty and unpredictability are the norms.
It is important to effectively share control between human operators and autonomous systems — whether it’s guiding a robot through a complex environment or completing tasks in a simulation. A key challenge is deciding when the human or the AI should take control. The paper below addresses this challenge by introducing a new framework for human-AI collaboration.
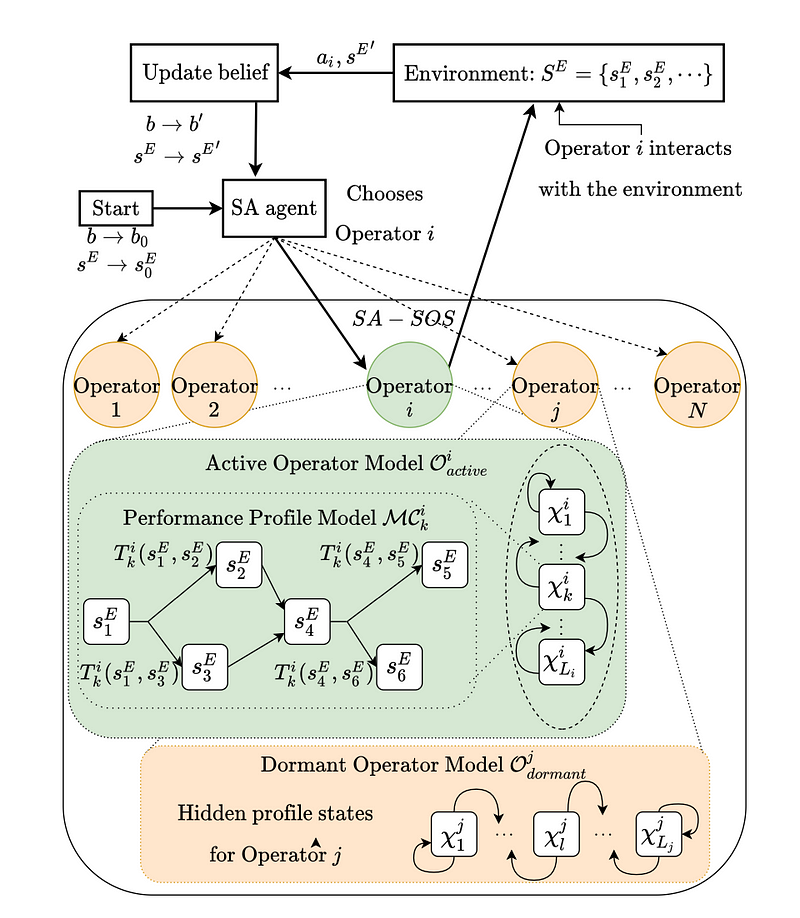
The framework is called SO-SAS: Stochastic Operators in Shared Autonomy Systems. SO-SAS represents a shift towards more realistic and flexible models of human performance in shared autonomy settings. Instead of assuming that human operators are always at their best, SO-SAS accounts for the variability in their performance due to unobservable factors like fatigue or experience.
Summary
As robotics continues to evolve, the need for robots that can interact and collaborate robustly in the real world is becoming increasingly critical. Current robots are often too specialized and lack the necessary sensory capabilities to function effectively at scale. The future of robotics lies in developing a new generation of robots equipped with advanced embodied intelligence, which can be divided into six key areas: Sense, Act, Interpret, Navigate, Coordinate, and Collaborate. By addressing these areas, researchers are paving the way for robots that are more intelligent, adaptable, and capable of working alongside humans in diverse environments. This comprehensive approach will ultimately enable robots to play a more significant role across multiple industries, driving innovation and improving efficiency in tasks ranging from complex industrial processes to everyday interactions.
References
[1] Engineering, Exploring and Exploiting the Building Blocks of Embodied Intelligence — An EPSRC Programme Grant
[2] Ouyang W, He L, Albini A, Maiolino P; 2022 IEEE 5th International Conference on Soft Robotics (RoboSoft)
[3] Shorthose O, Albini A, He L, Maiolino P; 2022 IEEE Robotics and Automation Letters
[4] Walter Goodwin, Sagar Vaze, Ioannis Havoutis, Ingmar Posner; Zero-Shot Category-Level Object Pose Estimation; Submitted on 7 Apr 2022
[5] Touching a NeRF: Leveraging Neural Radiance Fields for Tactile Sensory Data Generation; Zhong S, Albini A, Parker Jones OP, Maiolino P, Posner I
[6] Next Steps: Learning a Disentangled Gait Representation for Versatile Quadruped Locomotion; Mitchell AL, Merkt W, Geisert M, Gangapurwala S, Engelcke M, Parker Jones O, Havoutis I, Posner I
[7] Leveraging Scene Embeddings for Gradient-Based Motion Planning in Latent Space; Yamada J, Hung CM, Collins J, Havoutis I, Posner I
[8] Depth-SIMS: semi-parametric image and depth synthesis; Musat V, De Martini D, Gadd M, Newman P
[9] BoxGraph: semantic place recognition and pose estimation from 3D LiDAR Pramatarov G, De Martini D, Gadd M, Newman P
[10] Congestion-Aware Policy Synthesis for Multi-Robot Systems Street C, Pütz S, Mühlig M, Hawes N, & Lacerda B
[11] Multi-Unit Auctions for Allocating Chance-Constrained Resources Gautier A, Lacerda B, Hawes N, Wooldridge M
[12] Risk-Averse Bayes-Adaptive Reinforcement Learning; Rigter M, Lacerda B, & Hawes N
[13] Shared Autonomy Systems with Stochastic Operator Models Costen C, Rigter M, Lacerda B & Hawes N



