HYPRLABS Emerges from Stealth with HYPRDRIVE™, A "No-Priors" AI Architecture Learning Directly from Reality

Dec 18 2025
HYPRLABS Inc. is officially out of stealth mode — and HYPR.CO is now live.
From the founders themselves:
We founded HYPR on a simple belief: that robots learn best when they learn as they move. Today, we’re introducing HYPRDRIVE™, our AI for robotics that reflects the state-of-the-art work of our software team, led by Co-founder and Director of AI, Werner Duvaud. It operationalizes our founding belief and establishes a kick-ass competitive advantage.
Check out our CEO & Co-founder, Tim Kentley Klay, showcasing HYPRDRIVE™ on The Road to Autonomy Podcast.
Self-Driving on 33 Watts: How HYPR Labs Trained a Model tor Just $850
@TimKentleyKlay, CEO & co-founder of @HYPR joined @gbrulte on The Road to Autonomy podcast to discuss how a team of four engineers achieved autonomous driving in San Francisco using just 33 watts of compute
Self-Driving on 33 Watts: How HYPR Labs Trained a Model for Just $850@TimKentleyKlay, CEO & co-founder of @HYPR joined @gbrulte on The Road to Autonomy podcast to discuss how a team of four engineers achieved autonomous driving in San Francisco using just 33 watts of compute… pic.twitter.com/JzTO9ukXNJ
— The Road to Autonomy® (@RoadToAutonomy) December 16, 2025
Press Articles:
Dec 15 2025
AI system learns continuously, runs light, delivering energy-efficient, domain-general autonomy for real-world robotics use cases
SAN FRANCISCO, Dec. 15, 2025 /PRNewswire/ -- HYPRLABS Inc. (HYPR), an AI robotics company based in San Francisco and Paris, today emerged from stealth with HYPRDRIVE™, a paradigm-shifting AI architecture designed to maximize Learning Velocity — the speed at which a robot turns exposure into intelligence.
HYPRDRIVE™ represents a fundamental departure from traditional robotics. While the industry standard relies on "crutches" such as hand-coded rules, labeled data, classical simulation, and high-definition maps, HYPRDRIVE™ utilizes a proprietary technique called Run-time Learning (RTL). This self-actualizing autonomy stack intentionally rejects these priors, learning directly from the "fundamental domain" — the robot interacting with its environment in real-time.
"We see continual, live robotic learning as the new frontier — a differentiator that will separate the winners from the pack because it enables what we call Learning Velocity: how fast your AI stack can turn exposure into intelligence," said Tim Kentley Klay, Co-Founder and CEO of HYPR (previously Co-Founder of Zoox), "Our core thesis is that intelligence arises from learning relationships, and that minimizing the loss of that learning is optimal. This means robots will learn best, when they learn as they move in their fundamental domain."
The "Fundamental Domain" Advantage
HYPR contends that classical simulators and HD maps are merely approximations that inject "structural noise" into AI models, widening the simulation gap and reducing efficiency. By constraining the robot to learn with zero prior knowledge, HYPRDRIVE™ forces the system to infer the environment's dynamics from first principles, building an internal model that is coherent, efficient, and aligned with reality.
HYPRDRIVE™ leverages a three-phase continual learning pipeline designed to accelerate Learning Velocity:
- Foundational Learning: Human-operated driving seeds the model with real-world behavioral priors captured from raw sensory streams and actuator traces, avoiding brittle hand-coded logic or simulated scenes.
- Hybrid Learning: The AI drives under human supervision, where real-time Guidance Feedback (GF) from the driver, now critic, overrides to provide precise corrections, enabling practical in-situ Reinforcement Learning from Human Feedback (RLHF).
- Continuous Learning: Fleet-wide asynchronous Guidance Feedback signals and AI selected high-value experiences are streamed to the cloud for iterative model refinement, with only delta parameter changes in model weights transmitted back to robots, enabling rapid, safe, and scalable fleet adaptation and validation with minimal bandwidth.
Unprecedented Efficiency
The announcement is backed by real-world performance data from the company's test fleet in San Francisco. HYPRDRIVE™ recently navigated a challenging 20-minute route through downtown San Francisco utilizing a car powered by arguably the world's most minimal autonomy hardware stack that included five vision cameras and a single NVIDIA Orin AGX, consuming just 33 watts of power (roughly equivalent to charging a smartphone). To get granular that is 12W for camera processing, 9W CPU, and 12W for neural inference; including camera power, the total sense-and-compute budget is just 45W. This performance was achieved with 1,600 hours driving exposure.
Unlike conventional autonomy systems that depend heavily on HD maps, expensive sensor arrays, and massive compute clusters, HYPRDRIVE™ embraces zero prior knowledge at deployment, allowing intelligence to emerge through direct run-time exposure. This approach minimizes structural noise from tools such as classical simulators, yielding an AI stack that is inherently adaptable across robotic platforms and environments.
A Domain-General Future
"We are focused on creating domain-general autonomy through end-to-end physical AI that improves efficiently from real-time environment interaction and human feedback," said Werner Duvaud, HYPR Co-Founder and Director of AI. "It is the shift from programmed behavior to emergent capability."
HYPR plans to integrate HYPRDRIVE™ into a next-generation of novel robots designed for out-performance in key markets, starting with its first product debuting in 2026.
To view HYPRDRIVE™ in action and for more information, visit www.hypr.co.
About HYPRLABS
HYPRLABS, based in San Francisco, California and Paris, France creates paradigm-shifting AI-native robots that learn faster than real time, in situ. From city streets to racetracks, our systems adapt through immersive, live learning and define the future of intelligent movement.
For more information, visit www.hypr.co.
About Tim Kentley Klay
Tim Kentley Klay is the Co-Founder and original architect of Zoox, where he led the development of the world's first ground-up, homologated robotaxi. He served on the U.S. Department of Transportation's Advisory Committee on Automation in Transportation. Tim holds 125 granted patents across autonomy, software, and hardware, and has been recognized with over 100 design awards, including Advance Global Australian.
For more information, visit www.klay.co.
SOURCE HYPRLABS Inc.


INTRODUCING HYPRDRIVE™ OUR ARTIFICIAL INTELLIGENCE FOR ROBOTICS
At HYPRLABS, our conjecture is that robots learn best when they learn as they move. And HYPRDRIVE™ — our architecture for robotic learning at run-time, in-situ — is validation of that belief.
We see continual, live robotic learning as the new frontier — a differentiator that will separate the winners from the pack because it enables what we call Learning Velocity: how fast your AI stack can turn exposure into intelligence. We think Learning Velocity will be the defining metric of the AI era, and HYPRDRIVE™ is designed to maximize this velocity.
To achieve this, we pioneered a technique called Run-time Learning (RTL)1 — a hyper-efficient autonomy stack that intentionally rejects the “crutches” of traditional robotics such as hand-coded rules, labeled data, sensor calibration, classical simulation and high-definition maps – essentially any form of ground-truth injection.
Instead, HYPRDRIVE™ learns directly from run-time experience — the robot interacting with its environment in real-time. We call this the fundamental domain, and it’s through this domain alone that the robot builds and validates a continuously evolving understanding of itself and its world.
Why the Fundamental Domain is Optimal
Our core thesis is that intelligence arises from learning relationships, and that minimizing the loss of that learning is optimal.
Through this lens, one can see that classical simulators, HD maps, and hand-coded rules are approximations of relationships in the fundamental domain. They may appear useful, but in truth, they inject structural noise into the model — widening the reality gap — which reduces efficiency and performance. Conversely, constraining the robot to learn with zero prior knowledge forces it to infer the environment’s dynamics from first principles. In doing so, we find it builds an internal model of relationships and actions that is coherent, efficient, and aligned to reality.

While our approach for real-world robotics is unconventional, it is not without precedent in adjacent verticals. Consider the evolution of Google DeepMind’s learning architectures: AlphaGo was given the rules of Go and historical game data. It surpassed human performance. AlphaZero generalized the method to Go, chess, and shogi — using no historical data, only self-play, while still being given the rules. It outperformed AlphaGo. MuZero was given neither the rules nor game history — it had to infer the game’s dynamics through interaction alone. And it achieved performance equivalent to AlphaZero, but interestingly with lower computational cost — 1 GPU vs. AlphaZero’s 4 specialized TPUs.
For us, the signal is clear: self-interaction without priors yields superior performance, because learning in the fundamental domain minimizes error by avoiding misalignment between models and reality. Concretely, it is the simultaneous learning of policy, dynamics, and behavior within a shared latent vector space that enables the most coherent, efficient, and adaptive model for intelligence.
A highlight reel of HYPRDRIVE™ autonomously navigating San Francisco, showcasing real-world competence across dense urban conditions — all running on just 12 watts of neural inference.
While the demonstration above shows HYPRDRIVE™ driving a car, this was simply a proving ground for a broader goal: building a domain-general autonomy stack. The model contains no hand-tuned, task-specific rules, and begins with zero prior knowledge of cars or driving.
Instead, it learns entirely from run-time interaction, making it inherently adaptable to any robotic platform or environment. As exposure increases, so does capability — producing an expressive competence shaped by the structure of its deployment domain.
What follows is a look inside how we designed HYPRDRIVE™ to optimize Learning Velocity through a continual learning pipeline that turns exposure into intelligence.

Manual driving phase: the model is seeded with paired visual inputs and control actions.
FOUNDATIONAL LEARNING
Real‑World Priors
The process begins with a human-operated robot — in this case, a car. We mounted five vision cameras and connected them, along with CAN-bus vehicle telemetry, to an NVIDIA Orin AGX. As the instructor drives, HYPRDRIVE™ captures a foundational dataset that seeds a transformer-based, end-to-end, pixels-to-action conditional imitation model.
This dataset provides real sensory streams and actuator traces that encode human driving intelligence and the platform’s true dynamics. This is key because it means that behavioral priors are learned from reality, not rules or simulated scenes — with no hand‑coded logic to maintain, and nothing brittle to break.
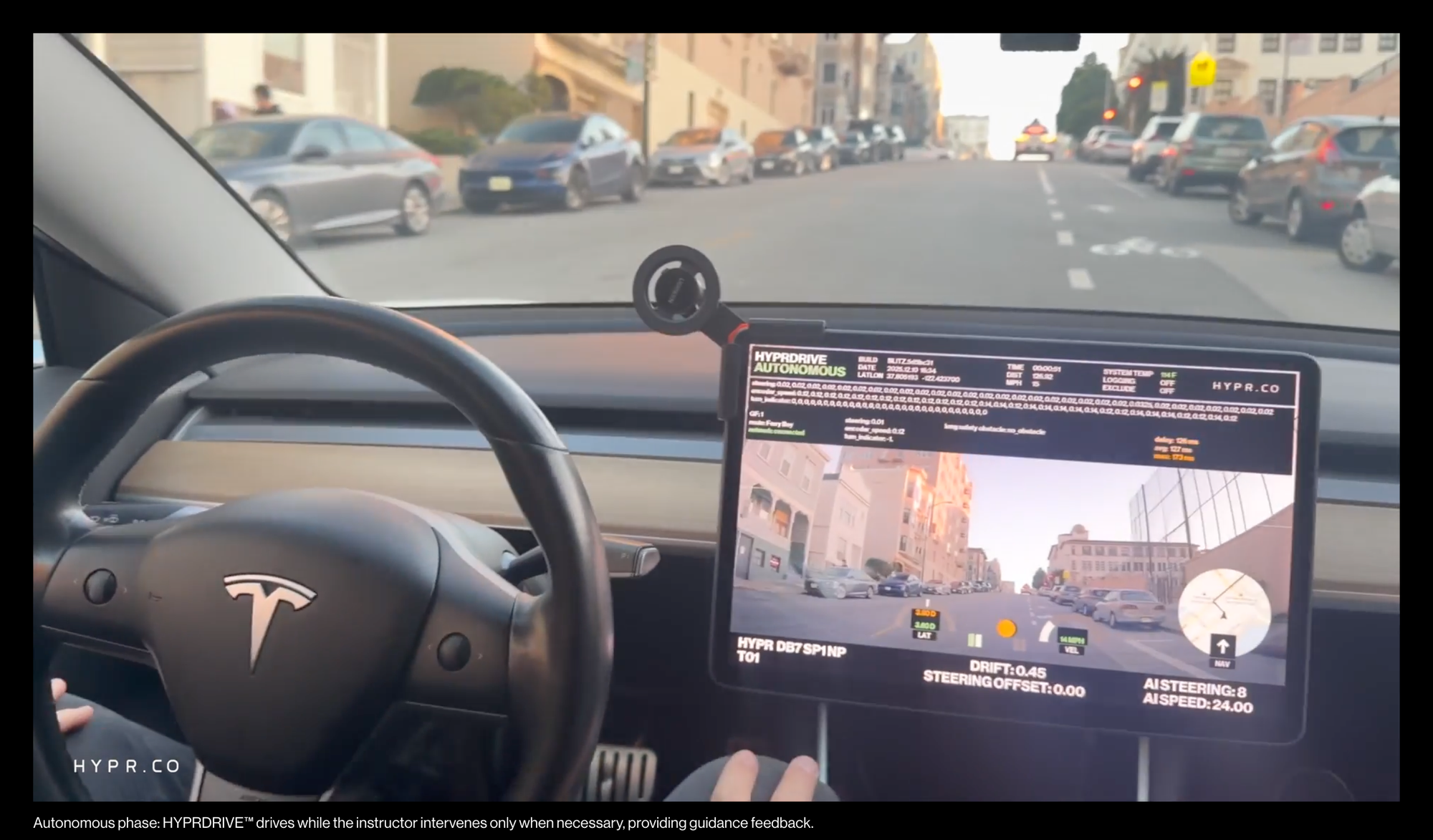
Autonomous phase: HYPRDRIVE™ drives while the instructor intervenes only when necessary, providing guidance feedback.
HYBRID LEARNING
Guided Autonomy In The Loop
With the base model trained, we switch to hybrid mode: where the AI drives under human supervision. If the AI makes a suboptimal decision, the driver can correct it in real-time, providing exactly the feedback gap the model needs to learn by overriding actuator input while the AI remains engaged. We call this Guidance Feedback (GF) — a practical form of in-situ Reinforcement Learning from Human Feedback (RLHF).
While our current fleet is modest — just two vehicles — the framework is designed for scale. As the fleet grows, it captures the stochastic variance of the real world through continuous exposure. The same fleet is then used to validate learning outcomes in-situ, creating a closed loop of correction, generalization, and self-verification.
We’ve developed additional techniques to enhance Learning Velocity. In-situ, all sensor streams and vehicle telemetry are embedded directly into the model’s latent space. This allows HYPRDRIVE™ to perform latent-space density estimation, identifying high-entropy (novel) situations — the rare, high-value experiences that meaningfully expand capability.
These high-value samples, combined with Guidance Feedback (GF) corrections, are compressed within the model’s latent space — achieving approximately 10:1 compression over the already compressed sensor data. The result is a representation compact enough to be efficiently streamed from robot to cloud, enabling low-bandwidth, real-time, fleet-scale learning.2

Connected fleet mode: vehicles continuously upload correction signals to the cloud, enabling run-time, in-situ model refinement and validation.
CONTINUOUS LEARNING
Fleet‑Scale Adaptation, Minimal Bandwidth
In the cloud, our framework ingests asynchronous “correction packets” streaming from the fleet — compressed embeddings of novelty and guidance feedback — and fine‑tunes the foundational model in iterative epochs.
Once regression tests pass, only the changed model parameters are transmitted back to the fleet — representing ~90% reduction in data transmission than naively syncing full models.
This real-world closed-loop process runs continuously, enabling rapid, safe, and efficient fleet-wide adaptation. Further, the foundational model itself, as it becomes more proficient, prunes redundant embeddings to compactify the dataset, ensuring every vector contributes uniquely to computational velocity.

Shot in San Francisco, October 2025.
PROVEN IN THE REAL WORLD
From SF With 🖤
The results aren’t theoretical. In the uncut demonstration video above, HYPRDRIVE™ navigates a complex, 20-minute route through downtown San Francisco — a representative robotaxi trip.
This performance was delivered using what we believe to be the world’s most minimal autonomy hardware stack: five vision cameras and a single NVIDIA Orin AGX, drawing just 33 watts — about the same power as charging a smartphone.
To get granular, that’s 12W for camera processing, 9W CPU and 12W for the neural inference. With camera power included, the total sense-and-compute budget is just 45W.
This performance was trained on a distilled corpus of ~1,600 hours of driving exposure, condensed from ~4,000 hours of raw collection — equivalent to approximately 16,000 miles at an average speed of 10 mph.
To train the model from scratch in the cloud cost us around $850.
While this level of efficiency is unprecedented, achieving safety-critical autonomy requires fleet-scale learning and validation. HYPRDRIVE™ is architected for exactly that — robotic fleets that get smarter with every mile, and learn faster as they grow.

HYPRDRIVE™ Heads-Up-Display. The heatmap depicted maps neural network activations projected back into pixel space — providing insight into how the model has learned to perceive its environment. The fact that this representation is unique from the familiar representations such as segmentation networks, depth-maps or box detectors is precisely the point: this is what real machine-vision looks like.
THE ARCHITECTURE OF LEARNING VELOCITY
Compounding exponentials means pipeline is king.
Alan Turing was a visionary who declared in a 1947 lecture that “what we want is a machine that can learn from experience.” Turing proposed that a truly intelligent machine should not just follow explicit instructions but should be able to modify its own programming based on the results of its behavior.
HYPRDRIVE™ is our step toward that ideal: a tight loop of real-world action, feedback, and adaptation that efficiently transforms exposure into intelligence. In an era of compounding exponentials, the metric that truly matters is learning velocity — the very frontier HYPRDRIVE™ was built to define.
1 Tim Kentley Klay, Werner Duvaud, Aurèle Hainaut, Maxime Deloche & Ludovic Carré, System and methods for training and validation of an end-to-end artificially intelligent neural network for autonomous driving at scale, U.S. Patent Application No. US20250005378A1 (filed June 29, 2024; published Jan. 2, 2025).
2 Patent pending.
HYPRLABS Inc. is not affiliated with Tesla Inc.; all trademarks remain the property of their respective owners.

For the last year and a half, two hacked white Tesla Model 3 sedans each loaded with five extra cameras and one palm-sized supercomputer have quietly cruised around San Francisco. In a city and era swarming with questions about the capabilities and limits of artificial intelligence, the startup behind the modified Teslas is trying to answer what amounts to a simple question: How quickly can a company build autonomous vehicle software today?
The startup, which is making its activities public for the first time today, is called HyprLabs. Its 17-person team (just eight of them full-time) is divided between Paris and San Francisco, and the company is helmed by an autonomous vehicle company veteran, Zoox cofounder Tim Kentley-Klay, who suddenly exited the now Amazon-owned firm in 2018. Hypr has taken in relatively little funding, $5.5 million since 2022, but its ambitions are wide-ranging. Eventually, it plans to build and operate its own robots. “Think of the love child of R2-D2 and Sonic the Hedgehog,” Kentley-Klay says. “It’s going to define a new category that doesn’t currently exist.”
For now, though, the startup is announcing its software product called Hyprdrive, which it bills as a leap forward in how engineers train vehicles to pilot themselves. These sorts of leaps are all over the robotics space, thanks to advances in machine learning that promise to bring down the cost of training autonomous vehicle software, and the amount of human labor involved. This training evolution has brought new movement to a space that for years suffered through a “trough of disillusionment,” as tech builders failed to meet their own deadlines to operate robots in public spaces. Now, robotaxis pick up paying passengers in more and more cities, and automakers make newly ambitious promises about bringing self-driving to customers’ personal cars.
But using a small, agile, and cheap team to get from “driving pretty well” to “driving much more safely than a human” is its own long hurdle. “I can’t say to you, hand on heart, that this will work,” Kentley-Klay says. “But what we’ve built is a really solid signal. It just needs to be scaled up.”
Old Tech, New Tricks
HyprLabs’ software training technique is a departure from other robotics’ startups approaches to teaching their systems to drive themselves.
First, some background: For years, the big battle in autonomous vehicles seemed to be between those who used just cameras to train their software—Tesla!—and those who depended on other sensors, too—Waymo, Cruise!—including once-expensive lidar and radar. But below the surface, larger philosophical differences churned.
Camera-only adherents like Tesla wanted to save money while scheming to launch a gigantic fleet of robots; for a decade, CEO Elon Musk’s plan has been to suddenly switch all of his customers’ cars to self-driving ones with the push of a software update. The upside was that these companies had lots and lots of data, as their not-yet self-driving cars collected images wherever they drove. This information got fed into what’s called an “end-to-end” machine learning model through reinforcement. The system takes in images—a bike—and spits out driving commands—move the steering wheel to the left and go easy on the acceleration to avoid hitting it. “It’s like training a dog,” says Philip Koopman, an autonomous vehicle software and safety researcher at Carnegie Mellon University. “At the end, you say, ‘Bad dog,” or ‘Good dog.’”
The multi-sensor proponents, meanwhile, spent more money up front. They had smaller fleets that captured less data, but they were willing to pay big teams of humans to label that information, so that the autonomous driving software could train on it. This is what a bike looks like, and this is how it moves, these humans taught the self-driving systems through machine learning. Meanwhile, engineers were able to program in rules and exceptions, so that the system wouldn’t expect, say, a picture of a bike to behave like a three-dimensional one.
HyprLabs believes it can sort of do both, and thinks it can squeeze a last-mover advantage out of its more efficient approach. The startup says its system, which it is in talks to license to other robotics companies, can learn on the job, in real-time, with very little data. It calls the technique “run-time learning.” The company starts with a transformer model, a kind of neural network, which then learns as it drives under the guidance of the human supervisors. Only novel bits of data are sent back to the startup’s “mothership,” which is used to fine-tune the system. Only the bits that are changed are sent back to the vehicle’s systems. In total, Hypr’s two Teslas have only collected 4,000 hours of driving data—about 65,000 miles’ worth—and the company has only used about 1,600 of those hours to actually train the system. Compare that to Waymo, which has driven 100 million fully autonomous miles in its decade-plus of life.
Still, the company isn’t prepared to run a Waymo-style service on public roads (and may operate in other, non-street contexts, too). “We’re not saying this is production-ready and safety-ready,” says Kentley-Klay, “But we’re showing an impressive ability to drive with an excruciatingly small amount of [computational work].”
The startup’s real test might come next year, when it plans to introduce its untraditional robot. “It’s pretty wild,” Kentley-Klay says.